We introduce SceneLinker, which generates context-consistent 3D scenes via semantic scene graph from RGB sequences.
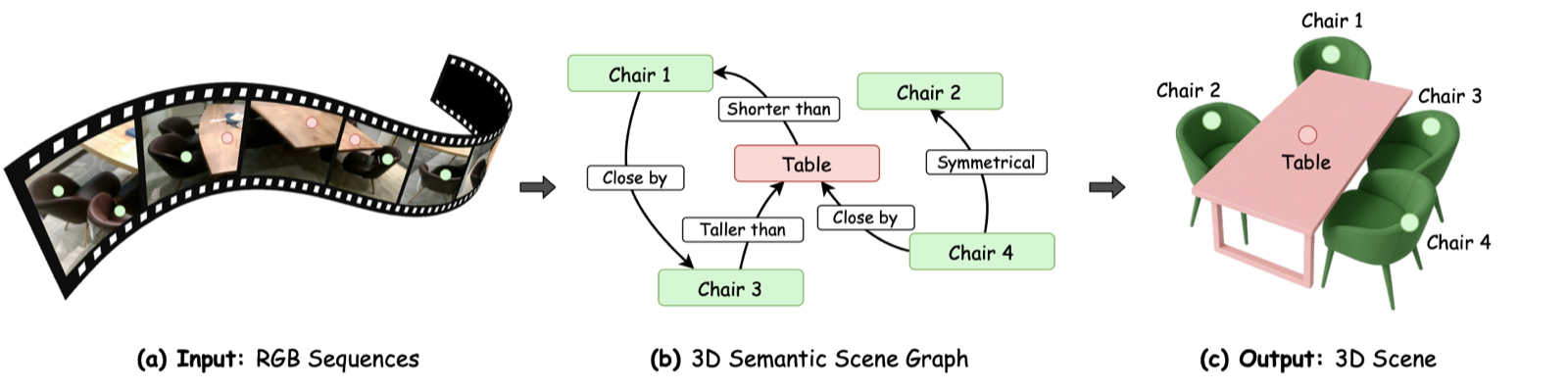
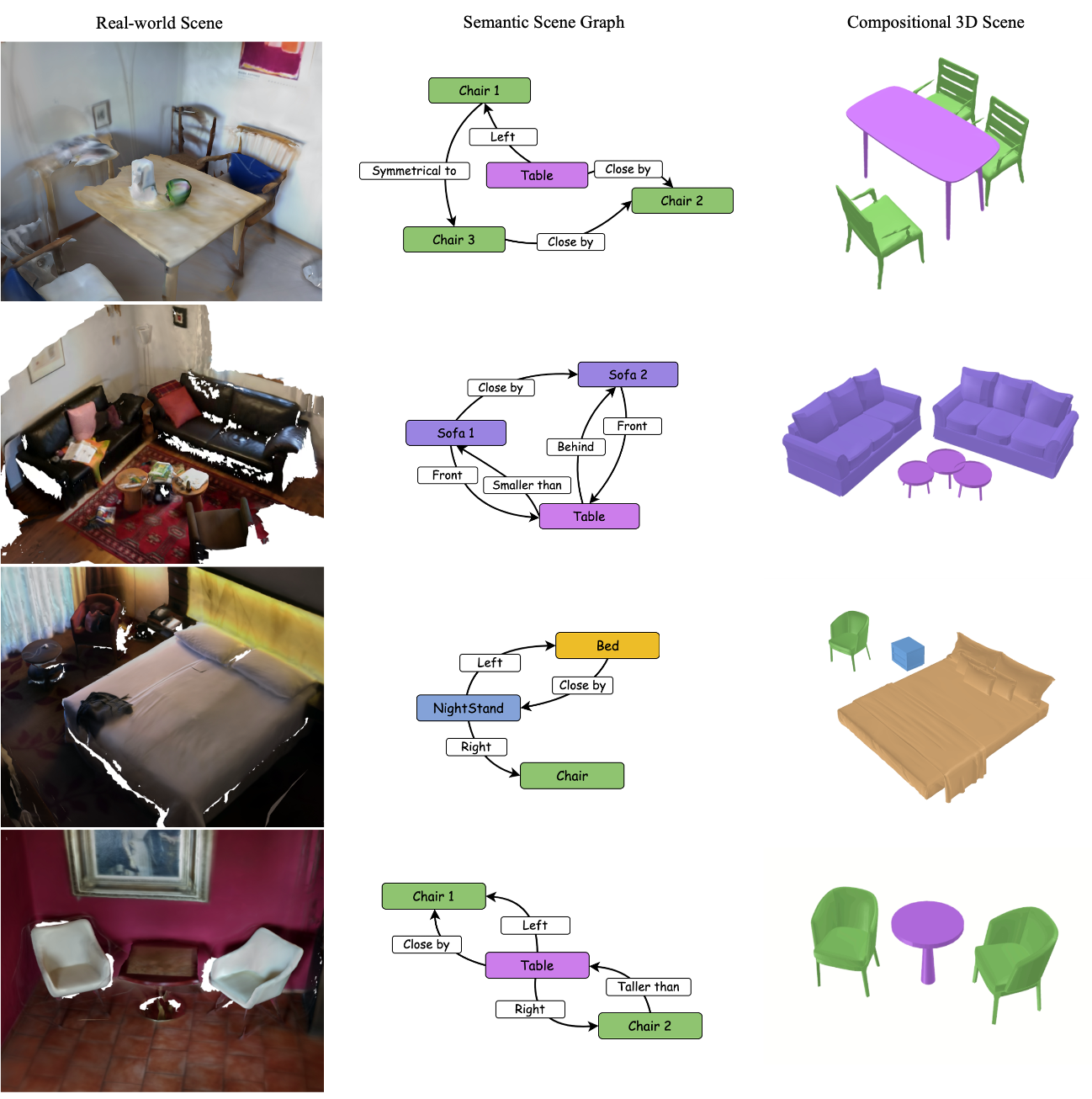
We introduce SceneLinker, a novel framework that generates compositional 3D scenes via semantic scene graph from RGB sequences. To adaptively experience Mixed Reality (MR) content based on each user's space, it is essential to generate a 3D scene that reflects the real-world layout by compactly capturing the semantic cues of the surroundings. Prior works struggled to fully capture the contextual relationship between objects or mainly focused on synthesizing diverse shapes, making it challenging to generate 3D scenes aligned with object arrangements. We address these challenges by designing a graph network with cross-check feature attention for scene graph prediction and constructing a graph-variational autoencoder (graph-VAE), which consists of a joint shape and layout block for 3D scene generation. Experiments on the 3RScan/3DSSG and SG-FRONT datasets demonstrate that our approach outperforms state-of-the-art methods in both quantitative and qualitative evaluations, even in complex indoor environments and under challenging scene graph constraints. Our work enables users to generate consistent 3D spaces from their physical environments via scene graphs, allowing them to create spatial MR content.
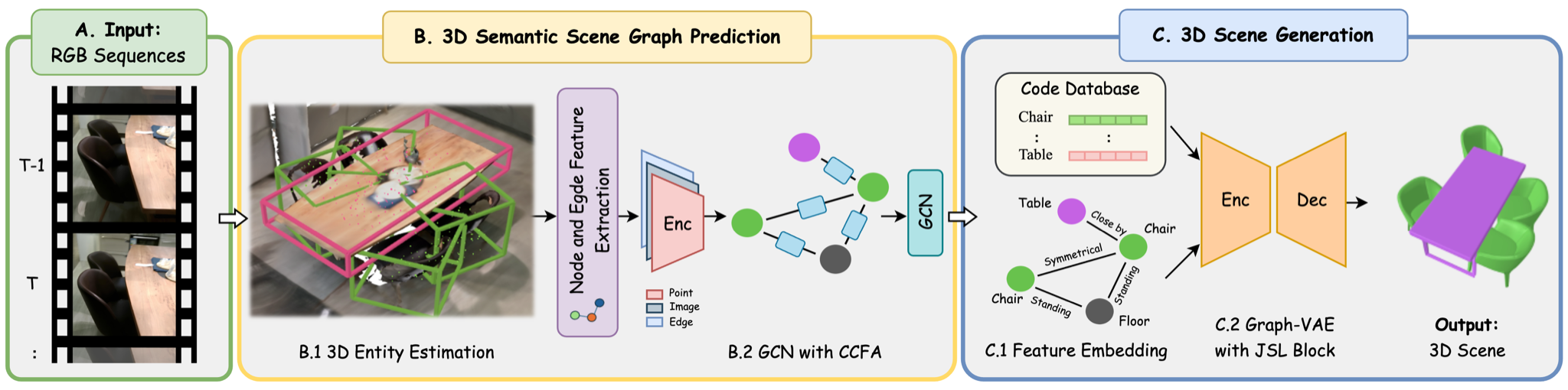
SceneLinker's goal is to represent the real world at the graph-level and to generate context-consistent 3D scenes. Our pipeline consists of two separate processes: (1) 3D scene graph prediction network with cross-check attention, and (2) Layout-centric 3D scene generation.
The first phase incrementally constructs segmented maps and point clouds using ORB-SLAM3 from image sequences to estimate 3D entities. These entities form nodes in a neighbor graph represented by oriented bounding boxes, multi-view images, and point features. We then apply an attention-based graph network to propagate robust message features between nodes and refine probability weights, resulting in a global scene graph.
In the second phase, the constructed graph and predicted bounding boxes are embedded into our scene generation network. Also, we enhance object and relationship features using a pre-trained CLIP, and assign initial shape priors to nodes using DeepSDF. Our Graph-VAE with a Joint Shape and Layout block (JSL block) fuses correlated shape and bounding box features, stably preserving object positions in graph-based generated scenes.
@article{kim2026scenelinker,
title={SceneLinker: Compositional 3D Scene Generation via Semantic Scene Graph from RGB Sequences},
author={Kim, Seok-Young and Kim, Dooyoung and Cho, Woojin and Song, Hail and Kang, Suji and Woo, Woontack},
journal={arXiv preprint arXiv:2602.02974},
year={2026}
} SceneLinker: Compositional 3D Scene Generation via
Semantic Scene Graph from RGB Sequences
SceneLinker: Compositional 3D Scene Generation via
Semantic Scene Graph from RGB Sequences